Here's the thing that'll tell you everything you need to know about Claude Opus 4.5's launch.
On 24 November 2025, developer Flavio Adamo posted his first impressions to X. The post got 2,626 likes and 446,000 views:
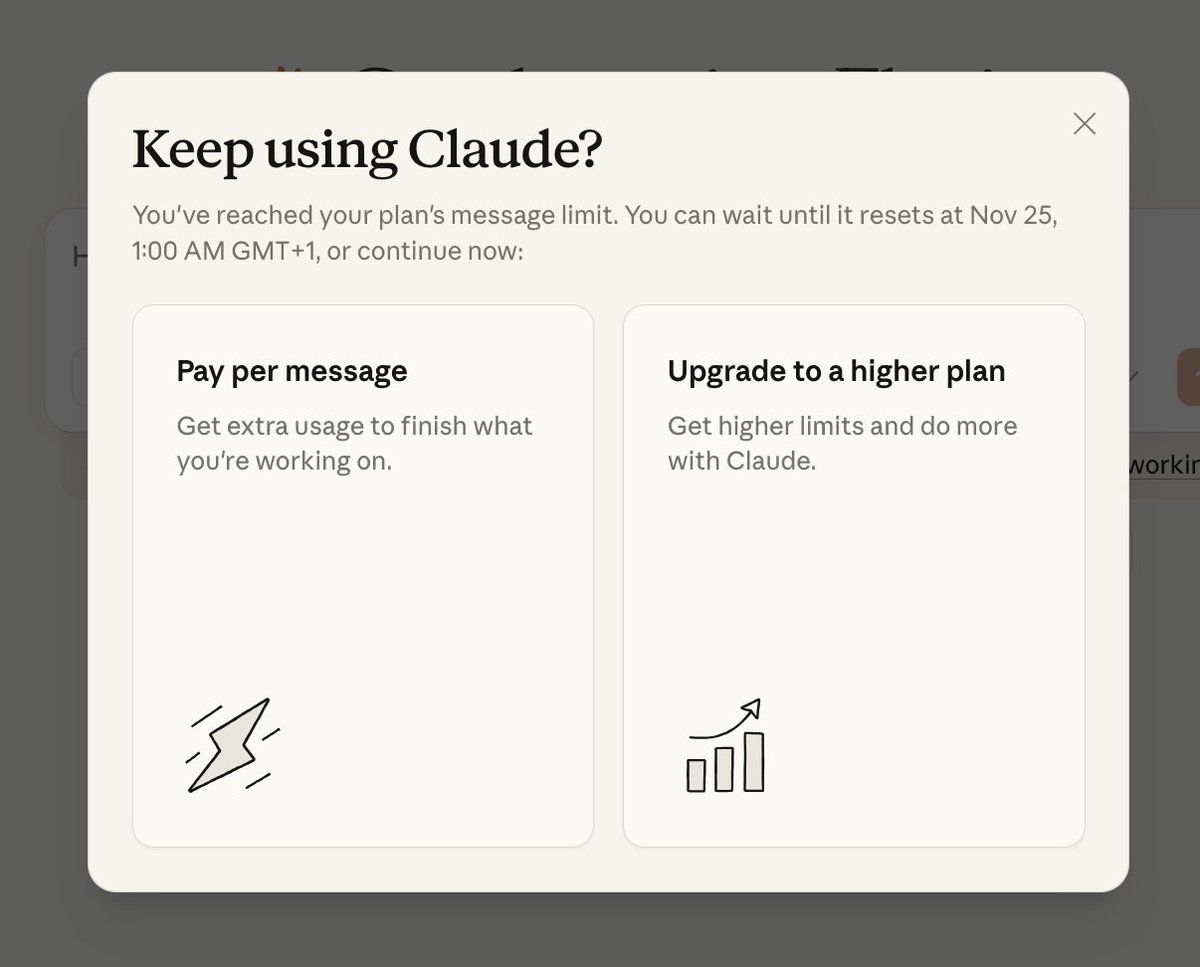
Four days later, developer Cooper posted his take. Also went viral (1,541 likes):
Same model. Two completely different realities.
I've spent the last two weeks watching this play out across X, Reddit, and Hacker News. (I've also spent way too much time debugging with Opus 4.5 myself, but that's a different story.) What I'm seeing isn't a simple "this model is good" or "this model is bad" situation. It's messier than that. More interesting, too.
What Anthropic Actually Shipped
Let's start with the specs, because they're genuinely impressive.
On 24 November 2025, Anthropic released Claude Opus 4.5 (model ID: claude-opus-4-5-20251101) with some serious numbers attached (Anthropic Announcement, 24 Nov 2025). The benchmark results caught everyone's attention:
- SWE-bench Verified: 80.9% (that's actual GitHub issue resolution, not toy problems)
- OSWorld: 66.3% (computer control tasks)
- ARC-AGI-2: 37.6% (reasoning challenges)
Context window's the same as Opus 4: 200,000 tokens in, 64,000 out. But here's what made developers actually sit up and pay attention. The pricing dropped from $15/$75 per million tokens to $5/$25. That's a 67% cut whilst delivering better performance.
On paper, this thing's a monster. And in some real-world tests, it backed up the hype.
The Developer Honeymoon Was Brief But Sweet
The first few days after release? Pure excitement.
GitHub's CPO Mario Rodriguez came out swinging: "Claude Opus 4.5 delivers high-quality code and excels at powering heavy-duty agentic workflows with GitHub Copilot. Early testing shows it surpasses internal coding benchmarks whilst cutting token usage in half" (GitHub Changelog, 24 Nov 2025).
Simon Willison (who's become something of a litmus test for model quality) posted his two-day sprint: 20 commits, 39 files changed, 2,022 additions. All with Opus 4.5 doing the heavy lifting (Simon Willison, 24 Nov 2025).
Then there was the 3D game demo. Someone built a working multiplayer game in a single session. The kind of thing that used to take dozens of back-and-forth iterations with previous models. It just... worked.
I'll be honest, I got caught up in it too. For about 36 hours, it felt like we'd hit a new plateau.
Then Reality Started Checking In
The rate limiting complaints started almost immediately.
Jason Lee didn't mince words: "Claude Opus 4.5 is still terrible at math and has super low rate limits even on the max plan... GPT 5.1 pro > gemini 3 >> opus 4.5 ~ grok" (Jason Lee, 24 Nov 2025). That's harsh, but he wasn't alone.
Here's where it gets properly weird. Multiple developers pointed out that Google's Anthropic offering (through their AI Studio) gives you HIGHER Opus 4.5 rate limits than Anthropic's own $20 Pro plan. Think about that for a second. You can get better access to Anthropic's flagship model by going through their competitor. The irony's not lost on anyone.
The Pokemon situation became a running joke. For context: there's an account called ClaudePlaysPokemon that's been trying to beat Pokemon Red using Claude models. It's a clever way to test long-term planning and memory. After two weeks with Opus 4.5, it still hasn't finished. Meanwhile, Gemini 2.5 Pro beat Pokemon Blue over six months ago. (I spent a genuinely embarrassing amount of time following this saga.)
But here's the complaint that showed up in several places, from Reddit to private Discord servers: memory and context issues. Levi Heaton put it bluntly on 7 December: "Claude opus 4.5 is garbage. He loses context from one prompt to the next. He constantly breaks code when applying edits... Opus 4.5 is a downgrade IDC what the benchmarks say" (Levi Heaton III, 7 Dec 2025). That's one developer's frustration, and plenty of others had completely different experiences. But the sentiment is worth noting.
That disconnect between benchmarks and real-world performance? It's the story of this release.
What's Actually Going On Here
I've read through probably 200+ developer posts at this point (yes, I need better hobbies), and a pattern's emerging. The model itself is genuinely excellent at specific tasks. Complex debugging, cross-system analysis, architectural decisions. The kind of work where you need deep reasoning and you're willing to wait for a thoughtful response.
But rapid iteration can be challenging when you hit rate limits. And that's where most developers actually spend their time.
Jake Eaton captured something interesting in his Pokemon experiment:

There's something oddly self-aware about that response.
The consensus I'm seeing on Reddit and Hacker News boils down to this: Opus 4.5 thinks really well, but it doesn't execute as reliably as you'd hope. It's the developer who comes up with brilliant solutions during architectural reviews but then struggles to remember what you discussed 20 minutes ago when it's time to write the actual code.
The Multi-Model Reality Nobody Wants to Admit
Here's what I'm seeing in practice, and what developers are actually doing.
Meng To laid out his workflow on 25 November:
That's three different models for three different jobs.
It's not elegant. It's not what any of us wanted. But it works.
I've fallen into a similar pattern. When I need to understand why a legacy system's behaving strangely, or when I'm migrating between frameworks, I'll use Opus 4.5. The reasoning quality's worth the wait. But for "fix this bug" or "add this feature," I'm reaching for GPT-5.1 or Gemini 3 Pro. They're faster, they're cheaper, and honestly? They're more reliable for straightforward work.
The pricing comparison tells the story:
- Claude Opus 4.5: $5/$25 per million tokens
- GPT-5.1: $1.25/$10 per million tokens
- GPT-5.2: $1.75/$14 per million tokens (released 11 Dec 2025)
- Gemini 3 Pro: $2/$12 per million tokens
Opus 4.5 costs 2.5x more than GPT-5.1 and nearly 2x more than GPT-5.2. That's fine if it's consistently better. But it's not. It's occasionally 10x better and occasionally 0.5x better, depending on the task.
Then OpenAI Dropped GPT-5.2 (Because Of Course They Did)
Right as I was finishing this analysis, OpenAI released GPT-5.2 on 11 December 2025. The timing wasn't coincidental.
According to TechCrunch, this was OpenAI's response to Google's Gemini 3 launch and Claude's momentum. Internal memos at OpenAI reportedly called the competitive situation a "code red." So they shipped GPT-5.2 with some genuinely impressive numbers.
The benchmarks that caught my attention (OpenAI announcement, 11 Dec 2025):
- GDPval: 70.9% win/tie rate vs human experts (first AI to exceed 50%)
- GPQA Diamond: 93.2% (Pro variant)
- AIME 2025: 100% (first AI to achieve this without tools)
- SWE-Bench Verified: 80.0%
Wait. Let's talk about that last one for a second.
Remember how Claude's big selling point was 80.9% on SWE-Bench Verified? OpenAI just matched it at 80.0%. They're essentially tied on the same benchmark. (The earlier claim that "Claude leads 80.9% vs 55.6%" was comparing different benchmarks. That 55.6% was GPT-5.2 on SWE-Bench Pro, which is a harder variant.)
The developer community's response has been... nuanced. I've been watching the X threads, and there's no clear winner emerging. Developer @thegenioo captured it well: "If you want a model that does what you say and you're willing to wait, 5.2 is incredible. If you want a (faster) model... Opus is great for that." Another developer, @amritwt, noted: "opus 4.5 is still better at code (bias towards speed)."
GPT-5.2 costs $1.75/$14 per million tokens. That's 40% more than GPT-5.1, but still cheaper than Claude. And OpenAI's offering three variants: Instant (speed), Thinking (complex work), and Pro (maximum accuracy at $21/$168). Plus a 400,000 token context window, double Claude's 200,000.
So now we've got THREE models with legitimate claims to "best for coding," all with different strengths, different pricing, and different use cases. The multi-model thesis didn't just survive GPT-5.2's release. It got stronger.
The Claude Code Factor
There's another wrinkle here that's not getting enough attention.
I've been using Claude Code (Anthropic's coding agent interface) pretty heavily. The same underlying Opus 4.5 model performs noticeably better in Claude Code than it does in the standard ChatGPT-style interface. We're talking "40% dumber without the right harness" levels of difference.
This matters because it suggests the model's capabilities are highly dependent on how you interact with it. The benchmark scores? Those are tested in carefully designed environments. Your mileage in a text box might genuinely vary.
John Coogan made an interesting observation about Anthropic's strategy:
That focus cuts both ways. They're brilliant at reasoning tasks. But they're behind on multimodal, they're behind on rate limits, and they're behind on the "just works" factor that makes a model feel reliable.
So What's the Actual Verdict?
After two weeks of watching developers work with this thing (and working with it myself), here's what I've landed on.
The Good:
- Genuinely best-in-class for complex reasoning tasks
- 67% cheaper than Opus 4 with better performance
- Matches GPT-5.2 on coding benchmarks at a fraction of the price
- Exceptional at architectural decisions and cross-system debugging
- Works brilliantly when paired with the right interface (Claude Code)
The Bad:
- Rate limits that can slow you down on the $20 Pro plan (though likely to improve as Anthropic scales)
- Context handling can be inconsistent in some workflows
- More expensive than GPT-5.1 and Gemini 3 Pro without being consistently better for simple tasks
The Verdict:
This is the best model for hard problems. That's not a limitation, that's a strength. Use it for complex reasoning, architectural decisions, and deep debugging. Use faster, cheaper models for straightforward tasks.
I wish I had a cleaner conclusion. "This model is great" or "this model is disappointing" would be easier to write. But that's not what's happening here. We're in a moment where the benchmarks are stellar, the technology is genuinely impressive, the pricing is remarkably competitive against GPT-5.2 Pro, and yes, the rate limits can be frustrating. But the capability is there, and it's remarkable.
And GPT-5.2's release two weeks after Opus 4.5 just reinforced that reality. We're not heading toward one dominant model. We're heading toward a world where you need to understand the strengths of multiple models and switch between them constantly. (That thought keeps me up at night, honestly.)
Cooper was right. This is the best model release for programming in a long time. And Flavio was right too. The rate limits make it borderline unusable for some workflows. Both things are true.
Welcome to December 2025, where the answer to "which AI model should I use" is increasingly "it depends what you're trying to do, and do you have access to three different subscriptions?"
The internet I grew up building had one browser, one language, one way to do things. This is messier. The workflow complexity is increasing, not decreasing. But it's also more interesting. (I'm including myself in that rationalisation, by the way.)
We're all figuring this out together. Nobody's got the perfect workflow yet. And with GPT-5.2, Claude Opus 4.5, and Gemini 3 all fighting for mindshare, I'm not sure anyone will anytime soon.